Java Memory Management
What you need to know to build fast and reliable software
About
Xceptance

- Focused on Software Test and Quality Assurance
- Performance Testing, Test Automation, Functional Testing, QA and Test Process Consulting
- Founded 2004
- Headquarters in Jena, Germany
- Subsidiary in Cambridge, MA, USA
- Performance Test Tool XLT, Java-based, APL 2.0
René Schwietzke

- Co-Founder and Managing Directory Xceptance
- Working with Java since version 1.0
- Performance Tester since 1999
-
@ReneSchwietzke
Sources
Always attribute other people's work



A Motivation
Java is quite efficient despite what many tell you

Disclaimer
A few words first
Java memory management is an ongoing challenge and a skill that must be mastered to have properly tuned applications that function in a scalable manner. Fundamentally, it is the process of allocating new objects and properly removing unused objects.
betsol.com
- There is no universal truth
- BUT these challenges are universal and apply to most languages
- Java makes things comfortable but comfort must be paid for
What lies ahead of you?
Just a quick view on the agenda
- What is this memory thing?
- Where and why do you need it?
- What are the main memory areas in Java?
- How much memory do you need?
- How much does memory cost?
Or in other words
- Allocate (new)
- Access (your code)
- Move (OS + GC)
- Free (OS + GC)
Memory in a Nutshell
What is this Memory Thing?
Memory
The very much unknown of modern languages
- Java does not have a memory notion
- There is data, but nobody knows where it is
- "Don't Care" concept, because memory handling is error-prone (greetings to all weekly browser patches)
- Classic language approach, e.g. C: I need room; OS, give me some room; I put something into the room... hopefully not too much; I visit the room, hopefully I stop at the wall; and I don't need the room anymore; OS, here is your room back
The Classic Pillars
- Registers: In CPU spaces where all the fun stuff happens
- Caches: Faster memory to close the gap to main memory (L1, L2, L3...), transparent (mostly)
- RAM: The physical memory
- Swap: Slower physical memory as extension of RAM
The Hardware Memory Layout
Oversimplified Memory Areas of Modern Hardware

The OS View of the Memory
Oversimplified OS View

The Java process
A rough view on the Java process memory areas (simplified)

Stack, Heap, Non-Heap
The basic memory sections of the JVM
- Stack: Local variables. references and method frames (call stack) are stored
- Heap: All
neware done here, except when Escape Analysis kicks in, layout depends on GC algorithm - Non-Heap: Java stores classes and other meta-data here (constant pool, field and method data...)
- Other: JVM code, internal runtime structures
- Code Cache: Compiled code is stored here, if exhausted, Java stops compiling
- Default stack on 64 bit Linux is 1024KB
- Heap can be sized with initial and max size, Java will determine the use of this large area mostly on its own
- Meta space (non-heap) can be sized as well, especially when a lot of classes are loaded, by default unlimited and growth as needed
- Initial code cache is 245,760 Kb, max is 251,658,240 Kb (PrintFlagsFinal does not match
-XX:+PrintCodeCache)
Memory Allocation
When, Where, and Cost
Stack and Register
Where does the JVM allocate?
- Most primitives live only in registers
- When registers are not sufficient (count), they are put on the stack
- Object references live in registers or on the stack as well
- No GC needed, no synchronization, just a pointer to the thread exclusive stack
- Stack limits, 1 MB in size by default
final static FastRandom r = new FastRandom(7L);
int a; int b;
@Setup
public void setup() {
a = r.nextInt(1000) + 128;
b = r.nextInt(1000) + 128;
}
@Benchmark
public int newInteger() {
Integer A = new Integer(a);
Integer B = new Integer(b);
return A + B;
}
@Benchmark
public int integerValueOf() {
Integer A = Integer.valueOf(a);
Integer B = Integer.valueOf(b);
return A + B;
}
@Benchmark
public int ints() {
int A = a;
int B = b;
return A + B;
}Stack and Register
final static FastRandom r = new FastRandom(7L);
int a; int b;
@Setup
public void setup() {
a = r.nextInt(1000) + 128;
b = r.nextInt(1000) + 128;
}
@Benchmark
public int newInteger() {
Integer A = new Integer(a);
Integer B = new Integer(b);
return A + B;
}
@Benchmark
public int integerValueOf() {
Integer A = Integer.valueOf(a);
Integer B = Integer.valueOf(b);
return A + B;
}
@Benchmark
public int ints() {
int A = a;
int B = b;
return A + B;
}
Benchmark Mode Cnt Score Error Units
newInteger avgt 3 24.187 ± 29.639 ns/op
newInteger:·gc.alloc.rate.norm avgt 3 32.000 ± 0.001 B/op
integerValueOf avgt 3 5.778 ± 10.026 ns/op
integerValueOf:·gc.alloc.rate.norm avgt 3 ≈ 10⁻⁶ B/op
ints avgt 3 5.145 ± 2.536 ns/op
ints:·gc.alloc.rate.norm avgt 3 ≈ 10⁻⁶ B/op
ints()
0x...fbcc: mov 0x10(%rsi),%eax
0x...fbcf: add 0xc(%rsi),%eax ; - ints@12 (line 55)
integerValueOf()
0x...264c: mov 0x10(%rsi),%eax ; - integerValueOf@-1 (line 44)
0x...264f: add 0xc(%rsi),%eax ; - integerValueOf@24 (line 47)
Heap
Where most of the garbage ends
- The famous heap that holds our objects
- Each object (arrays too) is allocated here
- GC moves around data over time
- TLAB (Thread Local Allocation Buffer): Thread exclusive part of the heap for zero-contention memory allocation
- If you have large objects, you overflow your TLAB and slow things down
- Heap design depends partially on GC

Heap
final static FastRandom r = new FastRandom(7L);
int a; int b;
@Setup
public void setup() {
a = r.nextInt(1000) + 128;
b = r.nextInt(1000) + 128;
}
@Benchmark
public int newInteger() {
Integer A = new Integer(a);
Integer B = new Integer(b);
return A + B;
}
0.50% 0x...3f0: mov $0x13a68,%r11d ; {metadata('java/lang/Integer')}
0.73% 0x...3f6: movabs $0x800000000,%rbp
0.03% 0x...400: add %r11,%rbp
0.26% 0x...403: mov 0x118(%r15),%rax ; TLAB "current"
0.30% 0x...40a: mov %rax,%r10 ; tmp = current
0.86% 0x...40d: add $0x10,%r10 ; tmp += 16 (object size)
0.30% 0x...411: cmp 0x128(%r15),%r10 ; tmp > tlab_size?
╭ 0x...418: jae 0x...4cc ; TLAB full, jump and request another one
0.50% │ 0x...41e: mov %r10,0x118(%r15) ; current = tmp (TLAB is fine, alloc!)
0.26% │ 0x...425: prefetchw 0xc0(%r10)
3.67% │ 0x...42d: mov 0xb8(%rbp),%r10
0.40% │ 0x...434: mov %r10,(%rax) ; store header to (obj+0)
4.14% │ 0x...437: movl $0x13a68,0x8(%rax) ; store klass {metadata(java/lang/Integer;)}
1.03% │ 0x...43e: movl $0x0,0xc(%rax) ; zero out the rest of the object
1.16% │ ↗ 0x...445: mov %rax,0x8(%rsp) ;*new
│ │ ; - org.sample.Allocation::newInteger@0 (line 36)
0.03% │ │ 0x...44a: mov (%rsp),%r10
0.43% │ │ 0x...44e: mov 0xc(%r10),%edx ;*getfield a
│ │ ; - org.sample.Allocation::newInteger@5 (line 36)
0.60% │ │ 0x...452: mov %rax,%rsi
0.66% │ │ 0x...455: xchg %ax,%ax
│ │ 0x...457: callq 0x00007fcf90401dc0 ; ImmutableOopMap{[0]=Oop [8]=Oop }
│ │ ;*invokespecial <init>
│ │ ; - org.sample.Allocation::newInteger@8 (line 36)
│ │ ; {optimized virtual_call}
1.19% │ │ 0x...45c: mov 0x118(%r15),%rax
1.59% │ │ 0x...463: mov %rax,%r10
│ │ 0x...466: add $0x10,%r10
0.93% │ │ 0x...46a: cmp 0x128(%r15),%r10
│╭│ 0x...471: jae 0x...4e1
0.66% │││ 0x...473: mov %r10,0x118(%r15)
0.46% │││ 0x...47a: prefetchw 0xc0(%r10)
4.70% │││ 0x...482: mov 0xb8(%rbp),%r10
0.03% │││ 0x...489: mov %r10,(%rax)
2.09% │││ 0x...48c: movl $0x13a68,0x8(%rax) ; {metadata('java/lang/Integer')}
1.06% │││ 0x...493: movl $0x0,0xc(%rax)
0.96% │││ 0x...49a: mov %rax,%rbp ;*new
│││ ; - org.sample.Allocation::newInteger@12 (line 37)
0.03% │││ 0x...49d: mov (%rsp),%r10
0.73% │││ 0x...4a1: mov 0x10(%r10),%edx ;*getfield b
│││ ; - org.sample.Allocation::newInteger@17 (line 37)
0.63% │││ 0x...4a5: mov %rbp,%rsi
│││ 0x...4a8: data16 xchg %ax,%ax
0.33% │││ 0x...4ab: callq 0x00007fcf90401dc0 ; ImmutableOopMap{rbp=Oop [8]=Oop }
│││ ;*invokespecial <init>
│││ ; - org.sample.Allocation::newInteger@20 (line 37)
│││ ; {optimized virtual_call}
1.16% │││ 0x...4b0: mov 0xc(%rbp),%eax
0.96% │││ 0x...4b3: mov 0x8(%rsp),%r10
0.50% │││ 0x...4b8: add 0xc(%r10),%eax ;*iadd
│││ ; - org.sample.Allocation::newInteger@32 (line 39
Escape Analysis
Stack vs. Heap is not longer really true
@Benchmark
public long array64()
{
int[] a = new int[64];
a[0] = r.nextInt();
a[1] = r.nextInt();
return a[0] + a[1];
}
@Benchmark
public long array65()
{
int[] a = new int[65];
a[0] = r.nextInt();
a[1] = r.nextInt();
return a[0] + a[1];
}
@Benchmark
public int[] array64Returned()
{
int[] a = new int[64];
a[0] = r.nextInt();
a[1] = r.nextInt();
a[3] = a[0] + a[1];
return a;
}
# -prof gc
Benchmark Mode Cnt Score Units
EscapeAnalysis.array64 avgt 2 30.378 ns/op
EscapeAnalysis.array64:·gc.alloc.rate.norm avgt 2 ≈ 10⁻⁵ B/op
EscapeAnalysis.array64Returned avgt 2 63.799 ns/op
EscapeAnalysis.array64Returned:·gc.alloc.rate.norm avgt 2 272.000 B/op
EscapeAnalysis.array65 avgt 2 65.819 ns/op
EscapeAnalysis.array65:·gc.alloc.rate.norm avgt 2 280.000 B/op
# -XX:EliminateAllocationArraySizeLimit=70
Benchmark Mode Cnt Score Units
EscapeAnalysis.array64Returned avgt 2 65.898 ns/op
EscapeAnalysis.array64Returned:·gc.alloc.rate.norm avgt 2 272.000 B/op
EscapeAnalysis.array65 avgt 2 30.855 ns/op
EscapeAnalysis.array65:·gc.alloc.rate.norm avgt 2 ≈ 10⁻⁶ B/op
No Garbage First
What the spec guarantees
- Java will never present us garbage data
- Because everything is initialized
- Every primitive is initialized
- Every array
- Every reference
No out-of-thin-air reads: Each read of a variable must see a value written by a write to that variable.
Data Consistency is not Free
We have to pay for well defined initial states
static Unsafe U;
int[] a;
@Param({ "1", "100", "1000", "10000", "1000000"})
int size;
long bytes;
long address;
@Setup(Level.Invocation)
public void setup() {
bytes = 4 * size + 4 + 12;
address = 0;
}
@Benchmark
public long unsafe() {
address = U.allocateMemory(bytes);
return address;
}
@Benchmark
public long unsafeInitialized() {
address = U.allocateMemory(bytes);
U.setMemory(address, bytes, (byte) 0);
return address;
}
@Benchmark
public long safe() {
a = new int[size];
address = 0;
return address;
}
Benchmark (size) Mode Cnt Score Units
safe 1 avgt 5 38.608 ns/op
safe 100 avgt 5 71.374 ns/op
safe 1,000 avgt 5 552.221 ns/op
safe 10,000 avgt 5 4,571.595 ns/op
safe 1,000,000 avgt 5 853,938.677 ns/op
unsafe 1 avgt 5 98.436 ns/op
unsafe 100 avgt 5 91.668 ns/op
unsafe 1,000 avgt 5 148.716 ns/op
unsafe 10,000 avgt 5 127.362 ns/op
unsafe 1,000,000 avgt 5 156.854 ns/op
unsafeInitialized 1 avgt 5 158.442 ns/op
unsafeInitialized 100 avgt 5 173.470 ns/op
unsafeInitialized 1,000 avgt 5 437.876 ns/op
unsafeInitialized 10,000 avgt 5 2,570.801 ns/op
unsafeInitialized 1,000,000 avgt 5 387,303.491 ns/op
Benchmark (size) Mode Cnt Score Units
safe:·gc.alloc.rate 1 avgt 5 144.246 MB/sec
safe:·gc.alloc.rate 100 avgt 5 1,550.342 MB/sec
safe:·gc.alloc.rate 1,000 avgt 5 3,854.734 MB/sec
safe:·gc.alloc.rate 10,000 avgt 5 5,459.355 MB/sec
safe:·gc.alloc.rate 1,000,000 avgt 5 2,995.923 MB/sec
Let's talk hardware
Java is hardware neutral!?
final int SIZE = 100_000;
final int[] src = new int[SIZE];
@Benchmark
public int step1() {
int sum = 0;
for (int i = 0; i < SIZE; i++)
{
sum += src[i];
}
return sum;
}
@Benchmark
public int step16() {
int sum = 0;
for (int i = 0; i < SIZE; i = i + 16)
{
sum += src[i];
}
return sum;
}
@Benchmark
public int step32() {
int sum = 0;
for (int i = 0; i < SIZE; i = i + 32)
{
sum += src[i];
}
return sum;
}
- Theory:
step16must be faster, about 16 times
Benchmark Mode Cnt Score Units Expected Actual
step1 avgt 2 41,528 ns/op 100%
step1Reverse avgt 2 41,657 ns/op 100.0% 100%
step1 avgt 2 41,528 ns/op 100%
step16 avgt 2 12,636 ns/op 6.3% 30.4%
step16 avgt 2 12,636 ns/op 6.3% 30.4%
step32 avgt 2 6,993 ns/op 50.0% 55.3%
- We got only 3.3x more speed
- What? Why?
- P.S. step16 results will vary a lot when running repeatedly
Cache Greetings
Benchmark Mode Cnt Score Units
step1 avgt 2 41,528 ns/op
step1:CPI avgt 0.866 #/op
step1:IPC avgt 1.154 #/op
step1:L1-dcache-load-misses avgt 6,062 #/op
step1:L1-dcache-loads avgt 96,620 #/op
step1:LLC-load-misses avgt 2 #/op
step1:LLC-loads avgt 32 #/op
step1:cycles avgt 100,055 #/op
step1:instructions avgt 115,507 #/op
step16 avgt 2 12,636 ns/op
step16:CPI avgt 1.244 #/op
step16:IPC avgt 0.804 #/op
step16:L1-dcache-load-misses avgt 6,132 #/op
step16:L1-dcache-loads avgt 6,181 #/op
step16:LLC-load-misses avgt 0 #/op
step16:LLC-loads avgt 4,111 #/op
step16:cycles avgt 30,922 #/op
step16:instructions avgt 24,855 #/op
step32 avgt 2 6,993 ns/op
step32:CPI avgt 1.375 #/op
step32:IPC avgt 0.727 #/op
step32:L1-dcache-load-misses avgt 3,047 #/op
step32:L1-dcache-loads avgt 3,122 #/op
step32:LLC-load-misses avgt 0 #/op
step32:LLC-loads avgt 2,808 #/op
step32:cycles avgt 17,244 #/op
step32:instructions avgt 12,542 #/op
step1Reverse avgt 2 41,657 ns/op
step1Reverse:CPI avgt 0.760 #/op
step1Reverse:IPC avgt 1.316 #/op
step1Reverse:L1-dcache-load-misses avgt 6,153 #/op
step1Reverse:L1-dcache-loads avgt 97,628 #/op
step1Reverse:LLC-load-misses avgt 1 #/op
step1Reverse:LLC-loads avgt 42 #/op
step1Reverse:cycles avgt 102,766 #/op
step1Reverse:instructions avgt 135,300 #/op
And now, we are very close to the hardware
- Step 1 and 16 have the same L1 load misses
- Step 32 half of it
- Loading from memory is expensive
- CPU gets bored when waiting for memory (low IPC)
- LLC: Lower-Level Cache (L2, L3...)
- CPI: Cycles per Instruction
- IPC: Instructions per Cycle
- 1 Cycle = 1 Hz
- T450s best possible IPC about 3.6
Hardware Metrics
Overview metrics provided by the OS
# step1
------------------------------------------------------------------------------
3801.896800 task-clock (msec) # 0,257 CPUs utilized
9,437,992,729 cycles # 2,482 GHz
10,850,555,712 instructions # 1,15 insn per cycle
582,384,283 branches # 153,183 M/sec
1,372,540 branch-misses # 0,24% of all branches
9,094,752,245 L1-dcache-loads # 2392,162 M/sec
569,785,405 L1-dcache-load-misses # 6,26% of all L1-dcache hits
2,360,265 LLC-loads # 0,621 M/sec
302,910 LLC-load-misses # 12,83% of all LL-cache hits
# step16
------------------------------------------------------------------------------
3841.234628 task-clock (msec) # 0,259 CPUs utilized
9,534.459,587 cycles # 2,482 GHz
7,401.297,634 instructions # 0,78 insn per cycle
1,847.661,610 branches # 481,007 M/sec
2.556,479 branch-misses # 0,14% of all branches
1,871,960,523 L1-dcache-loads # 487,333 M/sec
1,848,316,476 L1-dcache-load-misses # 98,74% of all L1-dcache hits
1,240,647,139 LLC-loads # 322,981 M/sec
167,504 LLC-load-misses # 0,01% of all LL-cache hits
About Caches
- Cache lines are 64 bytes
- Memory is read as 64 byte blocks, typically aligned
- 16x int size = 64 bytes, each access is a miss, because we read just the first four bytes
- 32x int size = 128 bytes, each access is a miss but we jump over a piece of memory, hence it is exactly twice as fast as 16x
- L1, L2 per core and partially shared by thread
- L3 per die aka multi-core
- Prefetching is going on hardware and software level
Cost - Nothing is Free
What it costs to leave the CPU
| Real | Humanized | |
|---|---|---|
| CPU Cycle | 0.4 ns | 1 s |
| L1 Cache | 0.9 ns | 2 s |
| L2 Cache | 2.8 ns | 7 s |
| L3 Cache | 28 ns | 1 min |
| Memory Access | 100 ns | 4 min |
| NVM SSD | 25 μs | 17 h |
| SSD | 50–150 μs | 1.5-4 days |
| HDD | 1–10 ms | 1-9 months |
| TCP SF to NY | 65 ms | 5 years |
| TCP SF to Hong Kong | 141 ms | 11 years |
- It costs 100 to 200 cycles when we have to go to main memory
- Hence Java and the CPU avoid main memory access at all cost
- Java doesn't give you the notion of a memory location, hence you cannot directly influence it
- Things will change with project Valhalla and its inline classes that brings primitive data type performance to "objects"
Data: She brought me closer to humanity than I ever thought possible, and for a time...I was tempted by her offer.
Picard: How long a time?
Data: 0.68 seconds, sir. For an android, that is nearly an eternity.
Memory Requirements
The Hidden Secrets of Memory Consumption
How big are things?
Just an Object, JVM Linux <32GB
=== Instance Layout ====================================
java.lang.Object object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 00 10 00 00 (00000000 00010000 00000000 00000000) (4096)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
==== Instance Graphed Layout=========================
java.lang.Object@4efac082d footprint:
COUNT AVG SUM DESCRIPTION
1 16 16 java.lang.Object
1 16 (total)
- You have to add 4 bytes for the reference to the object someplace else
- No reference means it can be GCed
How big are things?
Just an Object, JVM Linux >32GB or -XX:-UseCompressedOops
=== Instance Layout ====================================
java.lang.Object object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 50 8f 87 80 (01010000 10001111 10000111 10000000) (-2138599600)
12 4 (object header) da 7f 00 00 (11011010 01111111 00000000 00000000) (32730)
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
==== Instance Graphed Layout=========================
java.lang.Object@59505b48d footprint:
COUNT AVG SUM DESCRIPTION
1 16 16 java.lang.Object
1 16 (total)
Compressed oops (ordinary object pointer) represent managed pointers (in many but not all places in the JVM) as 32-bit values which must be scaled by a factor of 8 and added to a 64-bit base address to find the object they refer to. This allows applications to address up to four billion objects (not bytes), or a heap size of up to about 32Gb. At the same time, data structure compactness is competitive with ILP32 mode.
Object Header
The basic set of information of every object
- Stores information about the instance in the instance
- Can come in 8, 12, or 16 bytes
- Mostly 16 bytes on 64 bit without compressed class pointers, 12 bytes otherwise
- Under 32 GB, Java stores references in 4 bytes
- >= 32 GB, Java stores references in 8 bytes
- Object header: markword, classword
- classword: the reference to the class
- markword: metainfo about the object
64 bits:
--------
unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object)
JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object)
PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object)
size:64 ----------------------------------------------------->| (CMS free block)
unused:25 hash:31 -->| cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && normal object)
JavaThread*:54 epoch:2 cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && biased object)
narrowOop:32 unused:24 cms_free:1 unused:4 promo_bits:3 ----->| (COOPs && CMS promoted object)
unused:21 size:35 -->| cms_free:1 unused:7 ------------------>| (COOPs && CMS free block)How big are things?
An empty String
=== Instance Layout JDK11 - 32bit ====================================
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 09 00 00 00 (00001001 00000000 00000000 00000000) (9)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 08 18 00 00 (00001000 00011000 00000000 00000000) (6152)
12 4 byte[] String.value []
16 4 int String.hash 0
20 1 byte String.coder 0
21 3 (loss due to the next object alignment)
Instance size: 24 bytes
==== Instance Graphed Layout=========================
java.lang.String@d86a6fd footprint:
COUNT AVG SUM DESCRIPTION
1 16 16 [B
1 24 24 java.lang.String
2 40 (total)
=== Instance Layout JDK 11 - 64bit ===================================
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 11 00 00 00 (00010001 00000000 00000000 00000000) (17)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) d8 c1 11 04 (11011000 11000001 00010001 00000100) (68272600)
12 4 (object header) 90 7f 00 00 (10010000 01111111 00000000 00000000) (32656)
16 8 byte[] String.value []
24 4 int String.hash 0
28 1 byte String.coder 0
29 3 (loss due to the next object alignment)
Instance size: 32 bytes
==== Instance Graphed Layout=========================
java.lang.String@2892d68d footprint:
COUNT AVG SUM DESCRIPTION
1 24 24 [B
1 32 32 java.lang.String
2 56 (total)
How big are things?
An empty byte[]
=== Instance Layout Compressed ====================================
OFF SZ TYPE DESCRIPTION VALUE
0 8 (object header: mark) 0x0000000000000001 (non-biasable; age: 0)
8 4 (object header: class) 0x00000820
12 4 (array length) 0
12 4 (alignment/padding gap)
16 0 byte [B. N/A
Instance size: 16 bytes
Space losses: 4 bytes internal + 0 bytes external = 4 bytes total
==== Instance Graphed Layout=========================
[B@59717824d footprint:
COUNT AVG SUM DESCRIPTION
1 16 16 [B
1 16 (total)
=== Instance Layout 64 bit ====================================
[B object internals:
OFF SZ TYPE DESCRIPTION VALUE
0 8 (object header: mark) 0x0000000000000001 (non-biasable; age: 0)
8 8 (object header: class) 0x00007fdbc4ca8820
16 4 (array length) 0
16 8 (alignment/padding gap)
24 0 byte [B. N/A
Instance size: 24 bytes
Space losses: 8 bytes internal + 0 bytes external = 8 bytes total
==== Instance Graphed Layout=========================
[B@59717824d footprint:
COUNT AVG SUM DESCRIPTION
1 24 24 [B
1 24 (total) Size of String
String - Foobar - A JDK 11 Motivation too!
=== Instance Layout JDK8 - 32bit====================================
java.lang.String object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) da 02 00 f8 (11011010 00000010 00000000 11111000) (-134216998)
12 4 char[] String.value [F, o, o, b, a, r]
16 4 int String.hash 0
20 4 (loss due to the next object alignment)
Instance size: 24 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
==== Instance Graphed Layout=========================
java.lang.String@3f8f9dd6d footprint:
COUNT AVG SUM DESCRIPTION
1 32 32 [C
1 24 24 java.lang.String
2 56 (total)
=== Instance Layout JDK11 - 32bit====================================
java.lang.String object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 08 18 00 00 (00001000 00011000 00000000 00000000) (6152)
12 4 byte[] String.value [70, 111, 111, 98, 97, 114]
16 4 int String.hash 0
20 1 byte String.coder 0
21 3 (loss due to the next object alignment)
Instance size: 24 bytes
Space losses: 0 bytes internal + 3 bytes external = 3 bytes total
==== Instance Graphed Layout=========================
java.lang.String@3e27aa33d footprint:
COUNT AVG SUM DESCRIPTION
1 24 24 [B
1 24 24 java.lang.String
2 48 (total)
Size of char[6]
char[6] - Foobar
=== Instance Layout ====================================
[C object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 38 02 00 00 (00111000 00000010 00000000 00000000) (568)
12 4 (object header) 06 00 00 00 (00000110 00000000 00000000 00000000) (6)
16 12 char [C.<elements> 70, 0, 111, 0, 111, 0, 98, 0, 97, 0, 114, 0
28 4 (loss due to the next object alignment)
Instance size: 32 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
==== Instance Graphed Layout=========================
[C@13fd2ccdd footprint:
COUNT AVG SUM DESCRIPTION
1 32 32 [C
1 32 (total)
Size of String
String - Foobar vs. Foob😁r
=== Instance Layout JDK11 - 32bit ====================================
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 08 18 00 00 (00001000 00011000 00000000 00000000) (6152)
12 4 byte[] String.value [70, 111, 111, 98, 97, 114]
16 4 int String.hash 0
20 1 byte String.coder 0
21 3 (loss due to the next object alignment)
Instance size: 24 bytes
Space losses: 0 bytes internal + 3 bytes external = 3 bytes total
==== Instance Graphed Layout=========================
java.lang.String@3e27aa33d footprint:
COUNT AVG SUM DESCRIPTION
1 24 24 [B
1 24 24 java.lang.String
2 48 (total)
=== Instance Layout JDK11 - 32bit ====================================
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 08 18 00 00 (00001000 00011000 00000000 00000000) (6152)
12 4 byte[] String.value [70, 0, 111, 0, 111, 0, 98, 0, 61, -40, 1, -34, 114, 0]
16 4 int String.hash 0
20 1 byte String.coder 1
21 3 (loss due to the next object alignment)
Instance size: 24 bytes
Space losses: 0 bytes internal + 3 bytes external = 3 bytes total
==== Instance Graphed Layout=========================
java.lang.String@3e27aa33d footprint:
COUNT AVG SUM DESCRIPTION
1 32 32 [B
1 24 24 java.lang.String
2 56 (total)
Size of a wrapped primitive boolean
A class with a boolean and its loss
class A
{
boolean bar = true;
}=== Instance Layout ============ 32 bit =======================
org.jol.A object internals:
OFFSET SIZE TYPE DESCRIPTION
0 4 (object header)
4 4 (object header)
8 4 (object header)
12 1 boolean A.bar
13 3 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 3 bytes external = 3 bytes total=== Instance Layout ============ 64 bit =======================
org.jol.A object internals:
OFFSET SIZE TYPE DESCRIPTION
0 4 (object header)
4 4 (object header)
8 4 (object header)
12 4 (object header)
16 1 boolean A.bar
17 7 (loss due to the next object alignment)
Instance size: 24 bytes
Space losses: 0 bytes internal + 7 bytes external = 7 bytes totalMore Alignments
You gotta give
class A
{
String s;
boolean b1;
}=== Instance Layout == 32 bit =================================
org.jol.A object internals:
OFFSET SIZE TYPE DESCRIPTION
0 4 (object header)
4 4 (object header)
8 4 (object header)
12 1 boolean A.b1
13 3 (alignment/padding gap)
16 4 java.lang.String A.s
20 4 (loss due to the next object alignment)
Instance size: 24 bytes
Space losses: 3 bytes internal + 4 bytes external = 7 bytes total=== Instance Layout == 64 bit =================================
org.jol.A object internals:
OFFSET SIZE TYPE DESCRIPTION
0 4 (object header)
4 4 (object header)
8 4 (object header)
12 4 (object header)
16 1 boolean A.b
17 7 (alignment/padding gap)
24 8 java.lang.String A.s
Instance size: 32 bytes
Space losses: 7 bytes internal + 0 bytes external = 7 bytes total- References can only be stored with 4 byte alignment (32 bit) or 8 byte (64 bit)
- Full objects can only be stored with 8 byte (64 bit) alignment to each other
- Full 64 bit values can also only be stored fully aligned (double, long)
Reduce waste
JVM changes order to optimize layout
class A
{
String s1;
boolean b1;
int i1;
String s2;
boolean b2;
long i2;
}=== Instance Layout ====================================
org.jol.A object internals:
OFFSET SIZE TYPE DESCRIPTION
0 4 (object header
4 4 (object header)
8 4 (object header)
12 4 int A.i1
16 8 long A.i2
24 1 boolean A.b1
25 1 boolean A.b2
26 2 (alignment/padding gap)
28 4 java.lang.String A.s1
32 4 java.lang.String A.s2
36 4 (loss due to the next object alignment)
Instance size: 40 bytes
Space losses: 2 bytes internal + 4 bytes external = 6 bytes totalclass A
{
String s1;
boolean b1;
// int i1;
String s2;
boolean b2;
long i2;
}
=== Instance Layout ====================================
org.jol.A object internals:
OFFSET SIZE TYPE DESCRIPTION
0 4 (object header)
4 4 (object header)
8 4 (object header)
12 1 boolean A.b1
13 1 boolean A.b2
14 2 (alignment/padding gap)
16 8 long A.i2
24 4 java.lang.String A.s1
28 4 java.lang.String A.s2
Instance size: 32 bytes
Space losses: 2 bytes internal + 0 bytes external = 2 bytes total
More Memory Usage
To Raise Awareness
How big is...?
A empty HashMap
=== Instance Layout ====================================
java.util.HashMap object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000)
8 4 (object header) a5 37 00 f8 (10100101 00110111 00000000 11111000)
12 4 java.util.Set AbstractMap.keySet null
16 4 java.util.Collection AbstractMap.values null
20 4 int HashMap.size 0
24 4 int HashMap.modCount 0
28 4 int HashMap.threshold 0
32 4 float HashMap.loadFactor 0.75
36 4 java.util.HashMap.Node[] HashMap.table null
40 4 java.util.Set HashMap.entrySet null
44 4 (loss due to the next object alignment)
Instance size: 48 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
==== Instance Graphed Layout=========================
java.util.HashMap@1c655221d footprint:
COUNT AVG SUM DESCRIPTION
1 48 48 java.util.HashMap
1 48 (total)How big is...?
A HashMap with foo=bar?
=== Instance Layout ====================================
java.util.HashMap object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000)
8 4 (object header) a5 37 00 f8 (10100101 00110111 00000000 11111000)
12 4 java.util.Set AbstractMap.keySet null
16 4 java.util.Collection AbstractMap.values null
20 4 int HashMap.size 1
24 4 int HashMap.modCount 1
28 4 int HashMap.threshold 12
32 4 float HashMap.loadFactor 0.75
36 4 java.util.HashMap.Node[] HashMap.table [null, null, null, null, null, null, null, (object), null, null, null, null, null, null, null, null]
40 4 java.util.Set HashMap.entrySet null
44 4 (loss due to the next object alignment)
Instance size: 48 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
==== Instance Graphed Layout=========================
java.util.HashMap@10b48321d footprint:
COUNT AVG SUM DESCRIPTION
2 24 48 [B
1 80 80 [Ljava.util.HashMap$Node;
2 24 48 java.lang.String
1 48 48 java.util.HashMap
1 32 32 java.util.HashMap$Node
7 256 (total)
How big is...?
A HashMap with foo=bar and some usage?
=== Instance Layout ====================================
java.util.HashMap object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) a5 37 00 f8 (10100101 00110111 00000000 11111000) (-134203483)
12 4 java.util.Set AbstractMap.keySet (object)
16 4 java.util.Collection AbstractMap.values (object)
20 4 int HashMap.size 1
24 4 int HashMap.modCount 1
28 4 int HashMap.threshold 12
32 4 float HashMap.loadFactor 0.75
36 4 java.util.HashMap.Node[] HashMap.table [null, null, null, null, null, null, null, (object), null, null, null, null, null, null, null, null]
40 4 java.util.Set HashMap.entrySet (object)
44 4 (loss due to the next object alignment)
Instance size: 48 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
==== Instance Graphed Layout=========================
java.util.HashMap@10b48321d footprint:
COUNT AVG SUM DESCRIPTION
2 24 48 [B
1 80 80 [Ljava.util.HashMap$Node;
2 24 48 java.lang.String
1 48 48 java.util.HashMap
1 16 16 java.util.HashMap$EntrySet
1 16 16 java.util.HashMap$KeySet
1 32 32 java.util.HashMap$Node
1 16 16 java.util.HashMap$Values
10 304 (total)
Quick Summary
Just some of the previous facts summarized
- Java has primitive and object types
- Object types are mostly allocated on heap
- Primitive types in objects live on the heap
- Method local primitive types are kept on stack or in registers
- Method local object types live mostly on heap BUT the reference is stored on stack or kept in registers
- Objects have overhead, 12 to 24 bytes, does not include the stored data
- Everything is aligned to 8 bytes (aka 64 bit)
- So a boolean is one byte but when stored alone, you waste 7 bytes
- Memory access is 100-200 slower than a register operation
- JVM and CPU wants all in registers or caches
- Even avoids heap allocation when possible
Apply the Knowledge
GC can be your friend to achieve higher speed
GC can be your friend
Simplified memory layout for our test
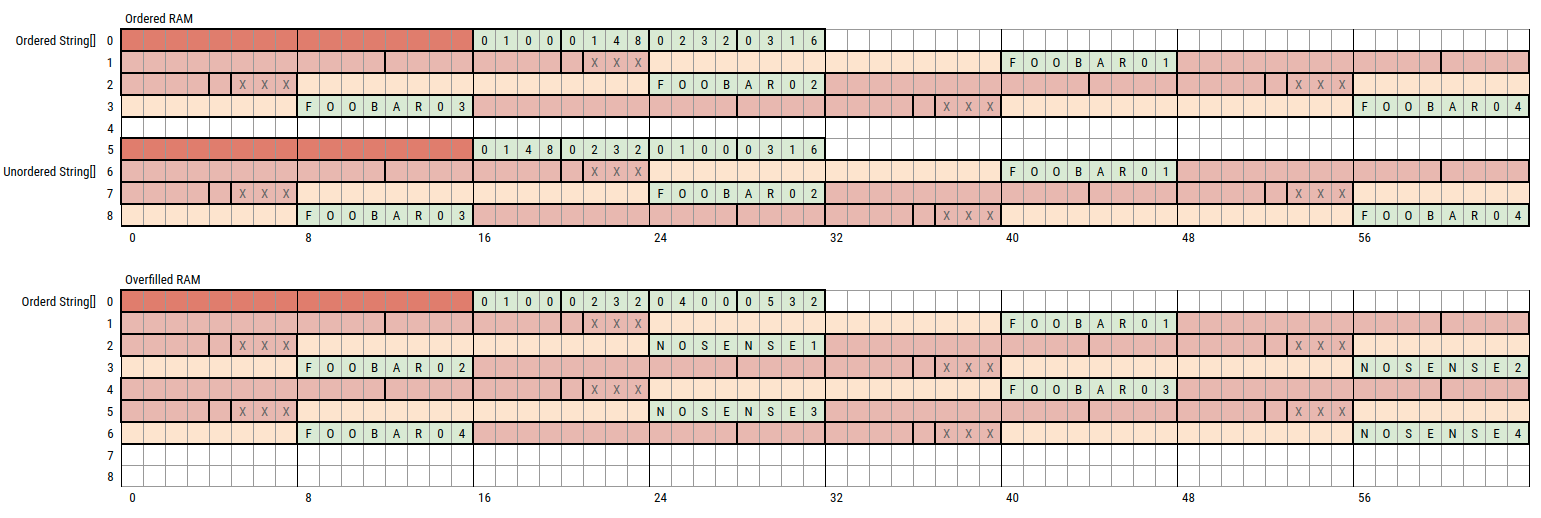
GC can be your friend
public class GCAndAccessSpeed
{
private final static int SIZE = 100_000;
private final List<String> STRINGS = new ArrayList<>();
private final List<String> ordered = new ArrayList<>();
private final List<String> nonOrdered = new ArrayList<>();
@Param({"false", "true"}) boolean gc;
@Param({"1", "10"}) int COUNT;
@Param({"false", "true"}) boolean drop;
@Setup
public void setup() throws InterruptedException
{
final FastRandom r = new FastRandom(7);
for (int i = 0; i < COUNT * SIZE; i++)
{
STRINGS.add(RandomUtils.randomString(r, 1, 20));
}
for (int i = 0; i < SIZE; i++)
{
ordered.add(STRINGS.get(i * COUNT));
}
nonOrdered.addAll(ordered);
Collections.shuffle(nonOrdered, new Random(r.nextInt()));
if (drop)
{
STRINGS.clear();
}
if (gc)
{
for (int c = 0; c < 5; c++)
{
System.gc();
TimeUnit.SECONDS.sleep(2);
}
}
}
@Benchmark
public int walk[Ordered|NonOrdered]()
{
int sum = 0;
for (int i = 0; i < [ordered|nonOrdered].size(); i++)
{
sum += [ordered|nonOrdered].get(i).length();
}
return sum;
}
}
Applied Memory Knowledge
- Theory is that memory closer together is good
- G1 is compacting, hence moving objects closer together
- When walking a structure with more "local" objects, the cache is hotter
- Verify with Non-GC setup aka EpsilonGC
# G1 GC
Benchmark (COUNT) (drop) (gc) Mode Cnt Score Units
walkNonOrdered 1 false false avgt 5 1,596,315.2 ns/op
walkOrdered 1 false false avgt 5 611,137.7 ns/op
walkNonOrdered 1 false true avgt 5 1,172,951.3 ns/op
walkOrdered 1 false true avgt 5 431,143.5 ns/op
walkNonOrdered 1 true false avgt 5 1,562,844.1 ns/op
walkOrdered 1 true false avgt 5 605,119.4 ns/op
walkNonOrdered 1 true true avgt 5 1,243,973.9 ns/op
walkOrdered 1 true true avgt 5 400,721.9 ns/op
walkNonOrdered 10 false false avgt 5 1,903,731.9 ns/op
walkOrdered 10 false false avgt 5 1,229,945.1 ns/op
walkNonOrdered 10 false true avgt 5 2,026,861.7 ns/op
walkOrdered 10 false true avgt 5 1,809,961.9 ns/op
walkNonOrdered 10 true false avgt 5 1,920,658.4 ns/op
walkOrdered 10 true false avgt 5 1,239,658.5 ns/op
walkNonOrdered 10 true true avgt 5 1,160,229.2 ns/op
walkOrdered 10 true true avgt 5 403,949.5 ns/op
# -XX:+UnlockExperimentalVMOptions -XX:+UseEpsilonGC
Benchmark (COUNT) (drop) (gc) Mode Cnt Score Units
walkNonOrdered 1 false false avgt 5 1,667,611.7 ns/op
walkNonOrdered 1 false true avgt 5 1,820,968.2 ns/op
walkNonOrdered 1 true false avgt 5 1,928,822.7 ns/op
walkNonOrdered 1 true true avgt 5 1,777,251.4 ns/op
walkOrdered 1 false false avgt 5 931,728.5 ns/op
walkOrdered 1 false true avgt 5 902,433.7 ns/op
walkOrdered 1 true false avgt 5 930,294.3 ns/op
walkOrdered 1 true true avgt 5 907,886.5 ns/op
Garbage Collections
The most distinct Java feature
GC in General
What you have to know in general
- Garbage Collection (GC) is nothing specific to Java
- Java just make the topic popular
- Less trouble managing the memory aka leaks
- Less chances of memory corruption
- Automatic freeing of not longer needed memory
- The luxury is paid for in parts by CPU and time
- Go has garbage collection
- JavaScript has garbage collection
- Python has garbage collection
- C# has garbage collection
- Rust has smart pointers and compiler managed memory
- Swift does ARC (Automatic Reference Counting)
A Theory First
What is the base motivation behind our current GCs
- Objects have different lifetime
- Imagine a cache or a method local
new - Objects have different size aka an array vs. an Integer
- Using one memory section will lead to heavy fragmentation aka contiguous memory section are getting smaller and later allocations will fail
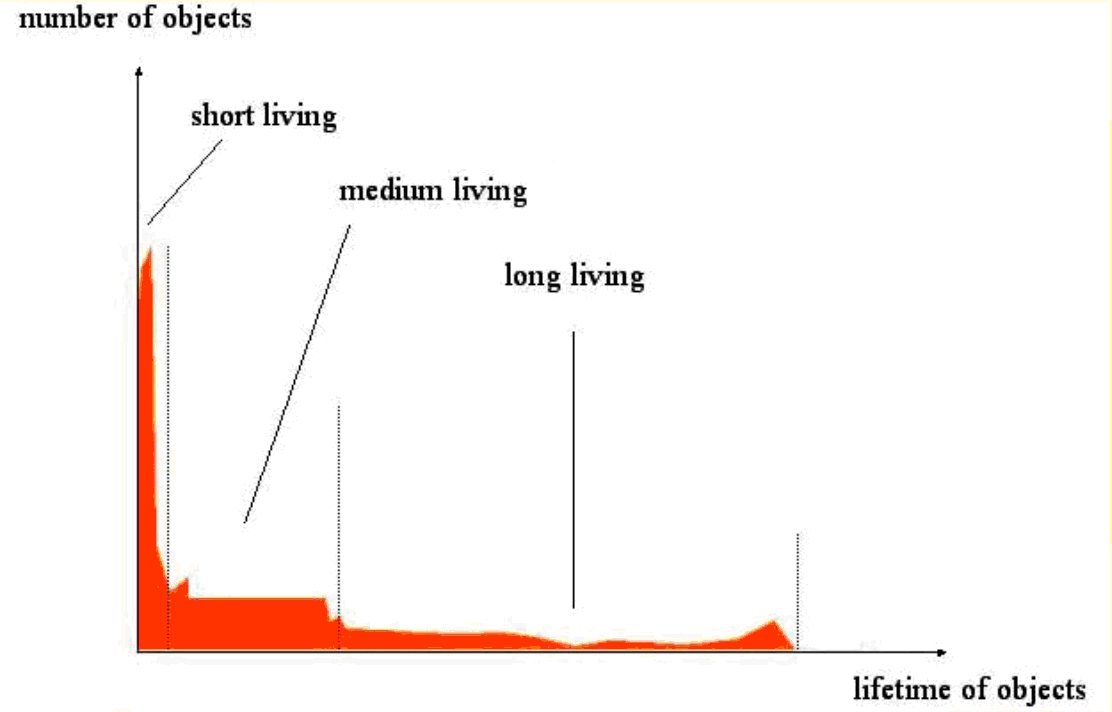
- Empirical studies showed that most objects don't live that long
- Storing long and short-lived objects next to each other is a bad idea
References
What you and the GC have to know
- A reference is the information where object data is located
- In C terms, a pointer to memory
- In Java terms, a reference to a pointer and a translation table
- Strongly reachable: An object is directly reachable from GC root without any reference types, no GC
- Softly reachable: An object is reachable by traversing a soft reference, GC possible when memory pressure or timer is up
- Weakly reachable: An object is reachable by traversing a weak reference, this object will be GCed when only weakly reachable (good for canonicalizing mappings)
- Phantom reachable: Not reachable otherwise, was finalized and a phantom reference refers to it
- Unreachable: When none of the above applies, qualifies for GC
Our Garbage Collectors today
What we have at our disposal today
- ParallelGC: Generational Collector, runs parallel for young and old [1]
- CMS: Generational Collector, parallel old, auto-combined with ParNew for parallel new [2]
- Epsilon GC: A No-Op-GC that does nothing besides providing memory, no cleanup of memory
- G1: Generational Collector, parallel, evacuating and compacting, made for large heaps [3]
- ZGC: A concurrent Garbage Collector, meaning all heavy lifting work is done while Java threads continue to execute (pause time at max 10 ms) - region based [4]
- Shenandoah GC: A low pause time Garbage Collector that reduces GC pause times by performing more garbage collection work concurrently - regionalized collector [5]
Let's be a Collector
Playing GC
Generational GC Lifecycle - Step 0
What ParallelGC and CMS do
- Heap is split into four resizable areas
- Eden: All allocations happen here, also known as "New"
- Survivor S0: Space for objects to live a little longer
- Survivor S1: Similar to S0, but only one is in active use at the time
- Tenured: Where surviving objects continue to live and where large allocations are made, also known as "Old"

Generational GC Lifecycle - Step 1
Let's use our memory

- Let's allocate some objects
- To simplify things, we ignore the size for now
- Important: If the object is too big, it will be allocated in Tenured directly
TLAB
Contention free allocation
- TLAB - Thread Local Allocation Buffer
- To avoid Eden contention, we split up Eden
- Area per thread exclusively assigned
- No synchronization needed
- Thread just bumps the pointer
- TLABs are resized dynamically
- Allocation is almost O(1) now

Generational GC Lifecycle - Step 2
Eden becomes full
- When the next allocation fails, Eden will be gc-ed
- Either all memory is allocated...
- ... or the next allocation request is bigger than free space
- Depending on algorithm, we either already marked objects or we stop and mark
- Unreferenced objects are discarded
- Referenced objects are hibernated in S0
- If the object does not fit, it goes to Tenured directly
- Eden has 0' now, the object that caused the GC


Generational GC Lifecycle - Step 3
Rinse and repeat
- Let's fill up Eden again
- When we run into GC, besides what we did before, we now also GC S0 and what survives there goes to S1
- S0/S1 object swapping happens until the survivor counter is up
- Object goes into Tenured afterwards
- When an object is in Tenured, the generation does not matter anymore
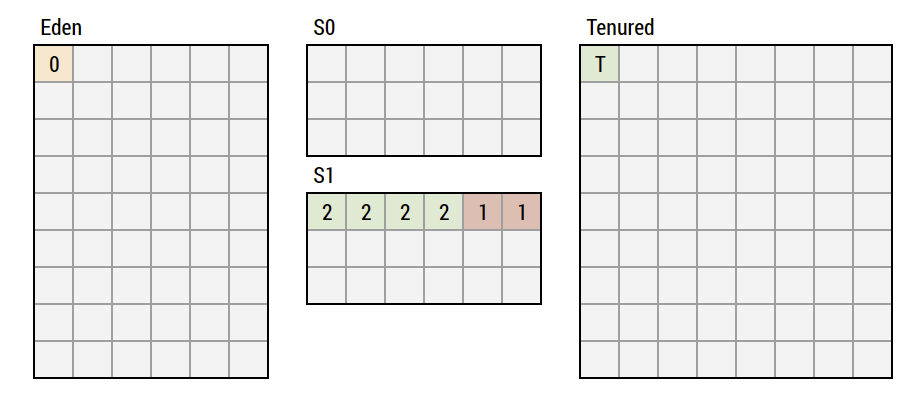
Generational GC Lifecycle - Step 4
Do another round
- Let's fill up Eden again and GC
- Assume that we have only two generations in S0/S1 so we move some to Tenured

Generational GC Lifecycle - Step 5
Assume we Eden GCed for a while...
- Now Tenured becomes full
- Either we reach a set limit or we cannot accommodate any new direct allocations or S0/S1 survivors
- CMS and ParallelGC start to mark live objects in parallel to running threads
- If your Tenured cannot accept survivors anymore, you have a Stop-the-World (STW) aka you run behind
- If you allocate large objects directly, your Tenured might be too fragmented, hence you STW to get compaction (CMS does not compact, ParallelGC does, it is STW all the time)

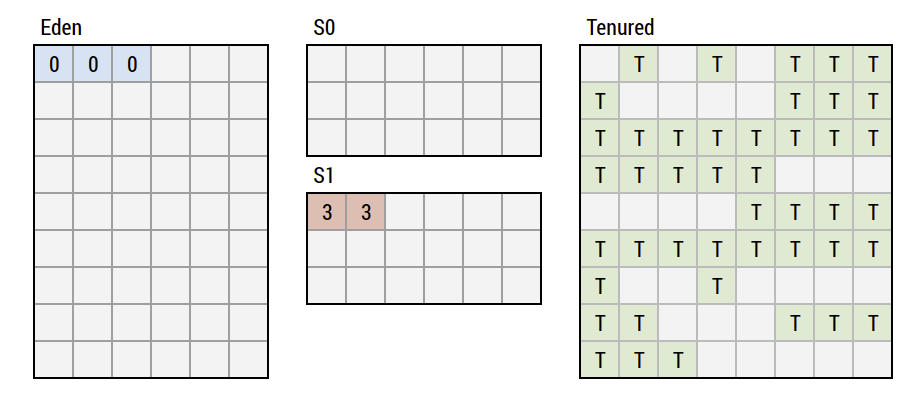
Issues and Challenges
Disadvantages of the classic GCs
- Either Eden or Tenured are cleaned
- All of that space is cleaned at once
- Limited capabilities to deal with large heaps aka 4GB or more
- Survivor spaces are limited in size (ratio to Eden)
- CMS trades pause time for fragmentation
- ParallelGC compacts but has issues with larger heaps
- Objects that don't fit Eden or TLAB section of Eden go directly to Tenured
- Many surviving objects might skip Survivor space because the Survivor size is too small
- Tenured has to finish quickly to avoid being the bottleneck when Eden has to copy through or allocate directly
G1 to the rescue
Fix the Problems
Addressing Known Issues
Keep things running in parallel to avoid stopping
- Garbage First (G1) was created to achieve these goals
- Easier tuning (CMS has 60 switches!)
- No premature promotion aka no S0/S1 notion
- Supporting big heaps better aka scale better
- Avoid fall back to STW collections (which happens with CMS when it cannot keep up or fragmentation is too big)
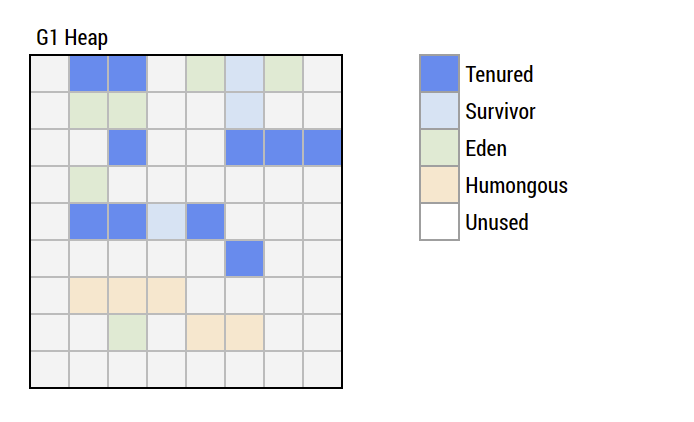
G1 - The Differences
What makes the G1 the G1
- Divide the heap in many regions of smaller size
- Every region serves a certain purpose (Eden, Survivor, Tenured, Humongous)
- Assignments are changed on the fly
- Survivor spaces aren't limited anymore
- Huge objects will be directly allocated in Humongous
- Object is humongous when larger than half a region
- Always fully evacuate a region (the compaction part) during GC
- Clean Tenured with a lot of garbage first (hence the name)
Regions
The part that is very important for G1
- 2k regions preferred, more possible, less might impact performance
- Area size 1MB, 2MB, 4MB, 8MB, 16MB, or 32MB
- Determined on startup based on Xms and Xmx
- Cannot be changed on the fly!!!
- Type of the region can change when region is empty
- Larger region size means more copy work during evacuation
| Xms | Xmx | Size | Regions |
|---|---|---|---|
| 1G | 1G | 1,024K | 1,024/1,024 |
| 1G | 2G | 1,024K | 1,024/2,048 |
| 1G | 10G | 1,024K | 512/5,120 |
| 2G | 5G | 1,024K | 2,048/5,120 |
| 5G | 5G | 2,048K | 2,560/2,560 |
| 10G | 10G | 4,048K | 2,560/2,560 |
| 24G | 24G | 8,192K | 3,720/3,720 |
Region Types
A region has a purpose
- Eden: Where new objects are created
- One region is selected and TLAB is used to allocate efficiently
- Eden region count is adjusted when needed (5% at start)
- Survivor: Where object live after an Eden collection (Young collection)
- Objects might survive several GC Young cycles
- At a certain threshold, survivor become Tenured
- Cycle count is dynamically adjusted, region count as well
- Tenured: Where the old objects live
- Long living objects, several seconds to minutes
- Humongous: Where the large objects live
- They get their own(!) regions when they are larger than 50% of region size
- Can span several regions
- Unused space is wasted
- Collected during Young
- Allocation of a humongous object triggers a mixed GC cycle
G1 - Humongous Challenges
Large can be too large
- Humongous objects waste space
- Humongous > 50% of a region
- Imagine 2.2 MB object with 1 MB region size
- Need three regions for it, wasting 0.8 MB
- Mostly arrays (also indirectly such as Strings)
- Humongous requires contiguous space
- Cause of fragmentation
- Humongous objects are kind of generation-less
- Used to be old, but nowadays collected during young
- Every humongous allocation trigger marking cycle
-XX:+G1ReclaimDeadHumongousObjectsAtYoungGC(default)- Instead of reclaiming humongous late we try to do it during Young collection now
- Still waste and fragmentation are a burden (first tuning target)
G1 - Young Collection
When Eden is full
- Eden is full (5% of heap initially)
- Scan all Eden regions
- Copy live objects to a survivor region
- Copy live objects from existing survivor regions (increment counter)
- No Eden is used anymore
- Calculate new statistics to tune Eden count

G1 - Young Collection II
When Eden is full again
- Survivors are older aka count is up
- Some Survivors become Tenured

G1 - Mixed Collection I
When we run out of space

- When we are at 45% total usage, we start marking in parallel
- Snapshot-at-the-beginning (SATB) and marking if objects are live or dead
- Objects created after SATB are not considered, aka always live
- We are calculating the liveness per region continuously
- Start a young cycle first after marking
- After that we do a old collection
- Collect most "dead" regions first hence the name Garbage First Collector
- Not all Tenured will be collected, count is based on target pause time and adjusted frequently
G1 - Mixed Collection II
Young Collection
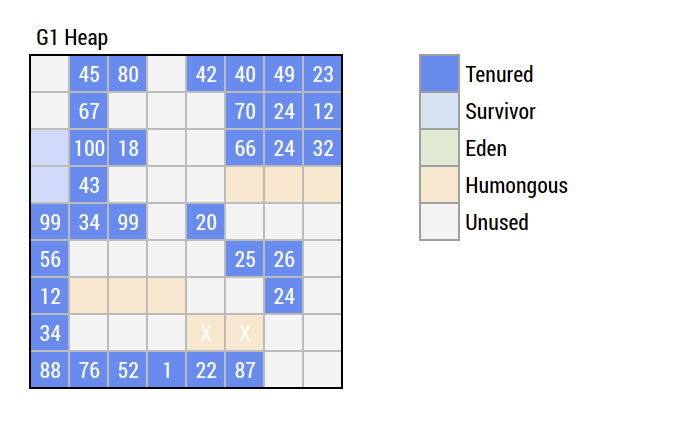
G1 - Mixed Collection III
Tenured Collection

G1 - Mixed Collection
- Will continue mixed collection (Eden and Tenured) until below threshold
- Going Young Collection only when "clean enough"
- G1 adjusts waste threshold and cycle count/frequency based on pause target goal
-XX:MaxGCPauseMillis=200- Desired pause goal in milliseconds
- Not guaranteed to be achieved
G1 -Full GC
Yes, G1 has full GC, but tries to avoid it
Metaspace
- Class unloading is not a FullGC anymore but the first reach of the metaspace will trigger a GC
[G1Ergonomics (Concurrent Cycles) request concurrent cycle initiation, reason: requested by GC cause, GC cause: Metadata GC Threshold]- Size the first occurrence properly, after first GC, JVM will manage the mark
-XX:MetaspaceSize=100M, default is about 20M on 64bit
to-Space exhausted
- We need space to copy to (evacuation collector!)
- If this space is too small, we fall back to FullGC
62.578: [GC pause (young) (to-space exhausted), 0.0406 secs] 62.691: [Full GC 10G->5813M(12G), 15.7221 secs]-XX:G1ReservePercent=20, 10% is default
G1 - Remaining Problems
Still G1 is not perfect
- Humongous objects are a burden
- Can cause fragmentation, never moved aka compacted
- Humongous can start an Mixed GC when the threshold is reached
- Humongous can trigger FullGC
- Humongous objects waste memory because they own their own regions and don't share that with others
- When we evacuate too much, we can fail and FullGC
- Tuning would fill another training
- Main goals: Avoid humongous objects and running into to-space exhaustion
- Besides that: Only no garbage is good garbage.
Some more Memory Stuff
Safepoints
Just an important internal fact
- JVM cannot halt threads, they have to cooperate
- For GC, all have to give up to get a consistent heap state
- Safepoint flag
- Each thread checks it frequently
- Can take some time, in theory also never happen
- See overhead with
-XX:+PrintSafepointStatistics-XX:+PrintGCApplicationStoppedTime
- In between two bytecodes or automatically inserted into compiled code
- Return from a method
- Each loop operation
- Automatically when blocked on monitor
- Automatically when in native code
vmop [threads: total initially_running wait_to_block] [time: spin block sync cleanup vmop] page_trap_count
18,373: ThreadDump [ 19 6 6 ] [ 3 0 3 0 0 ] 5
18,378: ThreadDump [ 19 6 6 ] [ 0 0 0 0 0 ] 5
18,462: ParallelGCFailedAllocation [ 19 8 9 ] [ 1 0 1 0 0 ] 8
18,617: ParallelGCFailedAllocation [ 19 4 6 ] [ 0 0 0 0 0 ] 4
18,768: ParallelGCFailedAllocation [ 19 9 10 ] [ 0 0 0 0 0 ] 9
18,918: ParallelGCFailedAllocation [ 19 4 5 ] [ 2 0 2 0 0 ] 4 JVM Memory and the OS
How does the JVM and the OS interact?
- JVM asks for all of
Xmxplus overhead when it starts - OS assigns virtual memory to it, when available or let's the process die
Xmsis virtual as well aka not turned into RSS right awayXmsis the first limit, JVM tries to live with that- If not possible we go to
Xmx, trying to get back toXmsif state permits
- OS memory can be fragmented due to the slow transition from virtual to RSS
- Use
-XX:+AlwaysPreTouchto avoid that, but you need the physical memory or OS will start paging when the JVM comes up - With a lot of rarely accessed Tenured objects and no GC, a GC on Tenured can cause the OS to page
- Pre-G1 GC often touched all of in use memory and caused heavy paging when memory is scarce
- Theoretically G1 touches more memory more often
Important to Know
Some things to know when dealing with memory
- Java gives out only clean memory
new int[1024]: 4112 bytes of memory are touched instantly by writing 0 to it- This turns virtual memory into RSS if not already RSS
- If you only use the first 100 bytes, you wasted a lot of cycles
- Off-Heap memory is allocated directly from the OS, but controlled by GC aka a reference to it is on the heap
- G1 is NUMA-aware aka memory closer to a CPU is used
- Might deliver up to 30% more performance
- Java fully manages the memory in use, not the OS (off-heap allocations excluded)